導入事例1 インターネット情報(画像)収集システム
画像が主な情報ソースとなる特定WEBページに対して、動的に更新されるその内容をユーザーが条件に従い再閲覧、再取得ができる事を目的としたシステムです。ユーザーはこれら情報をもとにその内容をデータ化し、インターネット上で新たなデータサービスを運営しています。
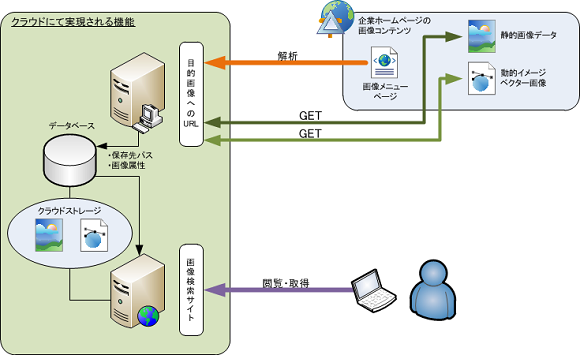
本システムの構築のポイントは、画像データという比較的データサイズの大きい情報を扱い、これを永続的に保管することが要件となっているため、ストレージコストの削減が重要なテーマであったこと。弊社はこれを解決するためシステム全域をクラウド上で展開することを設計の基本として開発をスタートしました。
システムの内容は画像収集対象となるWEBページをHTML解析し、目的画像に関連するURLを一定サイクルで監視し、既取得データとの差分比較により更新都度自動的に収集し、収集条件の属性情報とともに保持するクローラー部分と、それらで得た画像および属性情報を保存するストレージ部分、ユーザーが属性情報をもとに必要な画像情報を再閲覧することを可能とする機能を提供するUI部分により構成されておりそのすべてをクラウド化しています。
クローラーおよびUI部分はクラウド上の仮想サーバーにより運用し、ストレージ部分はより情報保持単価の低いクラウド上のストレージサービスにてまかなっています。
これらにより、スモールスタートでかつ拡張性に富むシステムが実現でき、またそれらを自動化できたことによる設計の自由度と運用コストの最適化を図りました。

{kind=link}
{kind=link}
{kind=link}